查询处理(Query Processing)
约 4743 个字 2 张图片 预计阅读时间 32 分钟
引言
查询处理是数据库系统将高级查询语言(如SQL)转换为低级操作指令并执行的过程。它是数据库系统性能的关键决定因素,影响查询响应时间和系统吞吐量。本章介绍查询处理的基本技术,包括各种关系操作的实现算法及其性能分析、查询执行策略以及现代查询处理的优化技术。
-
查询处理的基本阶段
查询处理通常分为三个主要阶段:
- 解析与翻译:将SQL查询转换为关系代数表达式
- 优化:选择最佳(成本最低)的执行计划
- 执行:运行选定的执行计划并返回结果
本章主要关注第三阶段,而第二阶段将在下一章详细讨论。
查询处理的挑战
关系代数表达式通常有多种等价形式,每个操作又有多种实现算法可供选择。例如:
- 连接操作可以用嵌套循环、排序合并或哈希算法实现
数据库系统的目标是从所有可能的执行计划中选择成本最低的一个。这需要:
- 估计每个操作的执行成本
- 使用统计信息进行成本预测
- 考虑各种算法的适用条件和性能特性
查询代价度量
-
查询代价的主要因素
查询执行的总时间受多种因素影响:
- 磁盘访问(通常是主要成本)
- CPU时间
- 内存使用
- 网络通信(分布式系统)
对于大多数数据库操作,磁盘I/O通常是主要的性能瓶颈。
磁盘访问成本
为简化起见,我们主要考虑两种磁盘访问成本:
- 块传输成本:将一个块从磁盘读入内存的时间 (\(t_T\))
- 磁盘寻道成本:将磁盘头移动到所需块位置的时间 (\(t_S\))
总的磁盘访问成本可表示为:
其中b是传输的块数,S是寻道次数。磁盘特性
不同存储设备的性能特性差异很大:
- 高端磁盘:\(t_S \approx 4\)毫秒,\(t_T \approx 0.1\)毫秒(4KB块)
- 固态硬盘(SSD):\(t_S \approx 20\)-\(90\)微秒,\(t_T \approx 2\)-\(10\)微秒(4KB块)
缓冲区考虑
许多算法可以通过使用额外的缓冲区空间来减少磁盘I/O:
- 可用内存大小会影响算法性能
- 通常假设最坏情况,即只有操作所需的最小内存可用
- 缓冲区中已有的数据可能避免额外的磁盘I/O
- 缓冲区替换策略(如LRU)会影响性能
选择操作
选择操作(σ)根据给定条件从关系中检索元组。针对不同查询条件和索引情况,有多种实现算法。
线性搜索
-
算法 A1:线性搜索
最简单的方法是扫描整个关系:
- 扫描每个块并测试所有记录是否满足选择条件
- 优点:适用于任何选择条件、任何文件组织方式
- 缺点:必须访问所有块,效率较低
成本:br次块传输 + 1次寻道(假设文件连续存储)
如果选择条件是关键字属性上的等值条件,找到匹配记录后可以停止扫描 (平均成本:br/2次块传输 + 1次寻道)
索引扫描
主索引,等值条件(键属性)
算法 A2:使用主索引查找满足等值条件的单个记录
- 成本:\((h_i + 1)(t_T + t_S)\),其中\(h_i\)是索引高度
主索引,等值条件(非键属性)
算法 A3:使用主索引查找满足等值条件的多个记录
- 假设匹配的记录存储在连续的块中
- 成本:\(h_i(t_T + t_S) + t_S + t_T \cdot b\),其中b是包含匹配记录的块数
辅助索引,等值条件
算法 A4:使用辅助索引进行等值查询
- 如果搜索键是候选键,只检索单个记录,成本:\((h_i + 1)(t_T + t_S)\)
- 如果搜索键不是候选键,检索多个记录:
- 每个匹配的记录可能在不同的块上
- 成本:\((h_i + n)(t_T + t_S)\),其中n是匹配的记录数
注意
对于非候选键上的辅助索引,如果匹配的记录数量很大,算法A4可能非常昂贵,此时线性扫描可能更优。
索引上的比较条件
算法 A5(主索引上的比较条件):
- 对于 A ≥ v 的条件,使用索引找到第一个 ≥ v 的元组,然后顺序扫描
- 对于 A < v 的条件,顺序扫描直到第一个 > v 的元组
算法 A6(辅助索引上的比较条件):
- 对于 A ≥ v 的条件,找到第一个 ≥ v 的索引项,然后顺序扫描索引
- 对于 A < v 的条件,扫描索引的叶页面直到第一个 > v 的条目
复杂选择条件
合取条件(AND)
算法 A7(使用一个索引的合取选择):
- 选择一个可以使用索引的条件σi进行选择
- 对检索的元组应用其他条件进行内存中过滤
算法 A8(使用复合索引的合取选择):
- 如果有合适的复合(多键)索引可用,直接使用该索引
算法 A9(通过标识符交集的合取选择):
- 要求使用指向记录的索引
- 对每个条件使用相应的索引,取得到的记录指针集合的交集
- 根据交集中的指针取出记录
析取条件(OR)
算法 A10(通过标识符并集的析取选择):
- 适用于所有条件都有可用索引的情况
- 对每个条件使用相应的索引,取得到的记录指针集合的并集
- 根据并集中的指针取出记录
否定条件(NOT)
通常使用线性扫描。如果很少的记录满足条件,且条件可使用索引,可以:
- 使用索引找到满足条件的记录
- 输出不在这些记录中的所有记录
排序
-
外部排序-合并
当数据量大于可用内存时,需要使用外部排序算法:
- 读入M大小的内存块进行内部排序,生成有序的"运行"
- 使用多路合并算法将有序运行合并成更长的有序运行
- 重复合并过程直到所有数据形成一个有序序列
外部排序-合并是处理大型关系的高效排序方法。
外部排序-合并算法
外部排序-合并算法的基本步骤:
-
创建初始运行:
- 读入每次能装入内存的最大数据块(M个块)
- 在内存中对这些数据进行排序
- 将排序后的数据块写出为一个"运行"
- 重复此过程直到处理完所有数据
-
合并运行:
- 使用N路合并(假设有足够内存,即N < M)
- 为每个输入运行分配一个缓冲区,为输出分配一个缓冲区
- 重复选择所有缓冲区中最小的记录,写入输出缓冲区
- 当缓冲区空时,读入相应运行的下一个块
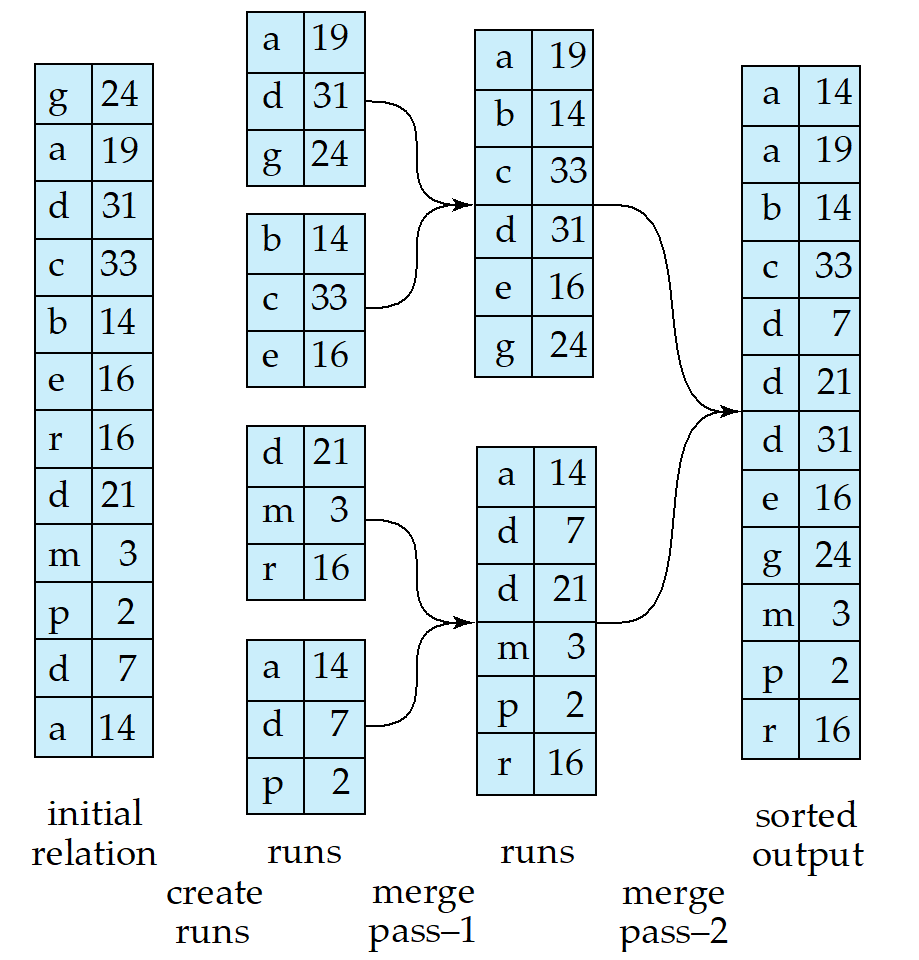
多趟合并
如果初始运行数量N大于可用内存块数M,则需要多趟合并:
- 每趟合并处理M-1个运行,生成更长的运行
- 一趟合并减少运行数量的因子为M-1
- 需要进行的合并趟数为\(\lceil\log_{M-1}(b_r/M)\rceil\)
外部排序-合并的成本分析
为减少寻道次数,每次读写\(b_b\)个块而不是单个块:
- 可以在一趟中合并的运行数:\(M/b_b - 1\)
- 需要的合并趟数:\(\lceil\log_{M/b_b-1}(b_r/M)\rceil\)
- 初始运行创建和每趟合并的块传输:\(2b_r\)
- 总块传输次数:\(b_r(2\lceil\log_{M/b_b-1}(b_r/M)\rceil + 1)\)
- 总寻道次数:\(2b_r/M + (b_r/b_b)(2\lceil\log_{M/b_b-1}(b_r/M)\rceil - 1)\)
例子
假设\(b_r = 1000, M = 10, b_b = 2\)
合并趟数 = \(\lceil\log_4(100)\rceil = 4\)
总块传输 = \(1000 \cdot (2 \cdot 4 + 1) = 9000\)
总寻道次数 = \(2 \cdot 1000/10 + (1000/2)(2 \cdot 4 - 1) = 200 + 3500 = 3700\)
连接操作
连接是关系数据库中最重要的操作之一,有多种实现算法,每种算法适用于不同场景。
-
连接算法比较
主要的连接算法包括:
- 嵌套循环连接:简单但通常效率较低
- 基于排序的连接:通过排序两个关系然后合并
- 基于哈希的连接:通过哈希分区降低比较次数
算法选择取决于关系大小、可用内存、索引可用性和连接条件类型。
嵌套循环连接
简单嵌套循环连接
for each tuple tr in r do begin
for each tuple ts in s do begin
test pair (tr,ts) to see if they satisfy the join condition
if they do, add tr • ts to the result
end
end
成本分析:
- 最坏情况:\(n_r \times b_s + b_r\)块传输,\(n_r + b_r\)次寻道
- 如果较小的关系能完全装入内存:\(b_r + b_s\)块传输,2次寻道
块嵌套循环连接
for each block Br of r do begin
for each block Bs of s do begin
for each tuple tr in Br do begin
for each tuple ts in Bs do begin
if (tr,ts) satisfy the join condition, add tr • ts to the result
end
end
end
end
成本分析:
- 最坏情况:\(b_r \times b_s + b_r\)块传输,\(2 \times b_r\)次寻道
- 使用M-2个块作为外部关系的缓冲单元:\(b_r/(M-2) \times b_s + b_r\)块传输
索引嵌套循环连接
如果内部关系的连接属性上有索引:
- 对外部关系的每个元组,使用索引查找内部关系中匹配的元组
- 成本:\(b_r(t_T + t_S) + n_r \times c\),其中c是使用索引查找匹配元组的成本
例子
计算student ⋈ takes,student为外部关系,takes上有ID的索引:
- 块嵌套循环连接成本:400*100 + 100 = 40,100块传输 + 200次寻道
- 索引嵌套循环连接成本:100 + 5000*5 = 25,100块传输和寻道
在这种情况下,索引嵌套循环连接更优。
排序-合并连接
排序-合并连接算法步骤:
- 对两个关系按连接属性排序(如果尚未排序)
- 类似归并排序的合并阶段,同时处理两个关系
- 需要特别处理连接属性上具有重复值的情况
成本分析:
- 如果关系已经按连接属性排序:\(b_r + b_s\)块传输 + \(b_r/b_b + b_s/b_b\)次寻道
- 如果关系未排序,需要加上排序的成本
哈希连接
-
哈希连接原理
哈希连接使用哈希函数对关系进行分区:
- 对两个关系使用相同的哈希函数进行分区
- 只需要比较哈希到相同分区的元组
- 每个分区独立处理,减少比较的总数量
- 通常比嵌套循环连接更高效,特别是对大型关系
基本哈希连接算法
-
构建阶段:
- 将关系s(较小的关系)分区到s0, s1, ..., sn
- 将关系r分区到r0, r1, ..., rn
- 使用相同的哈希函数h
-
探测阶段:
- 对每个i,将si装入内存并构建内存哈希索引
- 读取ri的元组,使用内存哈希索引查找匹配元组
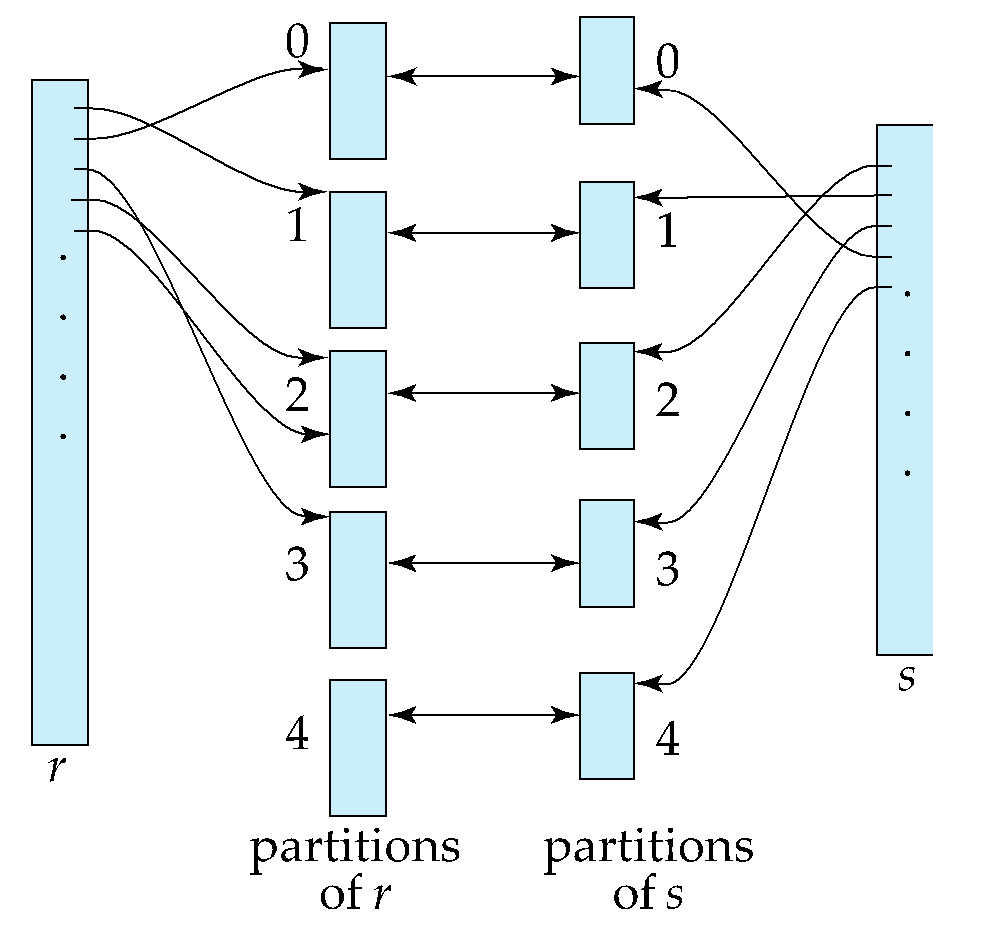
哈希连接的成本分析
如果不需要递归分区:
- 块传输:\(3(b_r + b_s) + 2 \cdot n\)
- 寻道次数:\(2(b_r/b_b + b_s/b_b) + 2 \cdot n\)
如果需要递归分区:
- 分区趟数:\(\lceil\log_{M/b_b-1}(b_s/M)\rceil\)
- 总成本:\(2(b_r + b_s)\lceil\log_{M/b_b-1}(b_s/M)\rceil + b_r + b_s\)块传输
优化
如果整个构建输入(较小的关系)能装入内存,不需要分区,成本降至\(b_r + b_s\)。
混合哈希连接
混合哈希连接的优化:
- 保留第一个分区(通常是分区0)的构建关系在内存中
- 对探测关系的第一个分区直接进行探测,无需写出
- 减少磁盘I/O,特别是当内存相对较大时
复杂连接条件
具有合取条件的连接
对于形如 \(r ⋈θ1∧θ2∧...∧θn_s\) 的连接:
- 使用嵌套循环/块嵌套循环连接,或者
- 计算一个简单连接的结果r ⋈θi s,然后应用其他条件
具有析取条件的连接
对于形如 \(r ⋈θ1∨θ2∨...∨θn_s\) 的连接:
- 使用嵌套循环/块嵌套循环连接,或者
- 计算为个别连接的并集:\((r ⋈θ1_s) ∪ (r ⋈θ2_s) ∪ ... ∪ (r ⋈θn_s)\)
其他操作
去重和投影
-
去重与投影实现
去重可以通过排序或哈希实现:
- 排序方法:排序后相同元组会相邻,删除重复项
- 哈希方法:相同元组会被哈希到同一个桶,可以检测并去除重复
投影操作通常是先执行投影,然后再进行重复消除。
优化技巧
- 在外部排序-合并的运行生成阶段以及中间合并步骤中也可以删除重复项
- 哈希方法与哈希连接类似,但不需要探测阶段的匹配
聚合操作
聚合可以用类似于去重的方式实现:
- 使用排序或哈希将同一组的元组聚集在一起
- 然后对每组应用聚合函数
优化:在运行生成和中间合并过程中合并同一组的元组,计算部分聚合值
- 对\(count\)、\(min\)、\(max\)、\(sum\):保存目前为止组内元组的聚合值
- 对\(avg\):保存\(sum\)和\(count\),最后除以\(count\)得到\(avg\)
集合操作
集合操作(并、交、差)可以使用排序变体或哈希变体实现。
基于哈希的并集操作:
- 使用相同的哈希函数对两个关系进行分区
- 对每个分区\(i\):
- 使用不同的哈希函数在内存中构建ri的哈希索引
- 处理\(s_i\):将\(s_i\)中的元组添加到哈希索引(如果它们不存在)
- 最后将哈希索引中的元组添加到结果中
基于哈希的交集和差集类似实现。
外连接操作
外连接可以通过以下方式计算:
- 先计算内连接,然后添加不参与的元组(填充空值)
- 修改连接算法以直接处理外连接
修改排序-合并连接:在合并过程中,对于不匹配的元组,输出填充空值的结果。
修改哈希连接:在探测阶段,记录哪些元组参与了连接,然后添加不参与的元组(填充空值)。
表达式求值
-
表达式求值策略
评估关系代数表达式的主要方法有两种:
- 物化:一次计算一个操作,将中间结果存储在磁盘上
- 流水线:同时执行多个操作,直接传递结果而不存储
流水线通常比物化更高效,但并非所有操作都适合流水线处理。
物化
物化评估过程:
- 一次计算一个操作,从最低层开始
- 使用存储在临时关系中的中间结果评估下一层操作
- 优点:始终可用
- 缺点:将中间结果写入磁盘然后再读回的成本可能很高
双缓冲技术:为每个操作使用两个输出缓冲区,当一个缓冲区已满时写入磁盘,同时另一个缓冲区正在填充
- 允许磁盘写入与计算重叠,减少执行时间
流水线
流水线评估同时执行多个操作,将一个操作的结果直接传递给下一个操作:
- 无需存储中间结果到磁盘
- 比物化更高效
- 但并非所有情况下都可行(例如,排序、哈希连接)
流水线的执行方式有两种:
-
需求驱动(延迟评估):
- 系统反复请求顶层操作的下一个元组
- 每个操作根据需要向子操作请求下一个元组
- 操作间需要维护"状态"
-
生产者驱动(急切流水线):
- 操作积极生产元组并将其传递给父操作
- 操作之间维护缓冲区
- 如果缓冲区已满,子操作等待直到有空间
迭代器模型
需求驱动流水线的典型实现是迭代器模型,每个操作实现以下接口:
- open():初始化操作
- next():生成下一个输出元组,并推进内部状态
- close():清理资源
阻塞操作
阻塞操作在消耗所有输入之前无法生成任何输出:
- 例如:排序、聚合、重复消除等
- 可以将阻塞操作分解为多个子操作
- 例如,将排序分为运行生成和合并两个子操作
流水线调度
-
流水线阶段
查询处理可以划分为流水线阶段:
- 同一阶段内的所有操作并行运行
- 一个阶段只能在前一阶段完成后开始执行
- 阻塞操作会导致流水线阶段的划分
良好的流水线调度可以显著提高查询执行性能。
有些算法无法在接收输入元组时就生成结果,例如合并连接或哈希连接。但可以使用算法变体来生成(至少部分)即时结果:
- 混合哈希连接:在内存分区的探测关系元组被读入时生成输出元组
- 双流水线连接:缓冲两个关系的分区0元组,在它们可用时读取,并输出匹配结果
现代查询处理技术
数据流和连续查询
数据流处理的特点:
- 数据以连续方式进入数据库(如传感器网络、用户点击等)
- 连续查询:结果随着流数据进入数据库而更新
- 通常使用窗口聚合(如滚动窗口将时间划分为小单位)
- 需要流水线处理算法
性能优化技术
-
现代优化技术
数据库系统使用多种技术提高查询处理性能:
- 查询编译:将查询直接编译为机器代码
- 列式存储:允许向量操作
- 缓存感知算法:优化数据访问模式
- 多线程并行处理:充分利用多核处理器
查询编译
将查询编译为机器代码可以避免解释开销:
- 避免重复从元数据查找属性位置
- 避免表达式求值的开销
- 通常通过生成Java字节码/LLVM,使用即时(JIT)编译
缓存感知算法
目标是最小化缓存未命中,充分利用缓存行中的数据:
- 排序:使用与L3缓存大小相当的运行(几兆字节)
- 哈希连接:
- 创建适合内存的分区
- 进一步子分区,使构建子分区和索引适合L3缓存
- 元组属性布局:经常一起访问的属性应相邻存储
并行查询处理
使用多线程进行并行查询处理:
- 缓存未命中会导致一个线程暂停,但其他线程可以继续
- 充分利用现代多核处理器
总结
查询处理是数据库系统性能的关键组成部分,涉及多种算法和优化技术:
- 算法选择:不同的关系操作有多种实现算法,每种算法适用于不同场景
- 成本估计:基于I/O操作数量、CPU使用和内存需求评估查询执行计划
- 执行策略:物化与流水线技术影响查询执行效率
- 现代优化:编译查询、缓存感知算法和并行处理进一步提高性能
有效的查询处理需要同时考虑硬件特性(如磁盘、内存和CPU)和数据特性(如关系大小、索引可用性和数据分布)。随着硬件和应用需求的发展,查询处理技术也在不断演进。